Abstract
Despite the impressive performance of large language models across various tasks, they often struggle with reasoning under negated statements. Negations are important in real-world applications as they encode negative polarity in verb phrases, clauses, or other expressions. Nevertheless, they are underrepresented in current benchmarks, which mainly include basic negation forms and overlook more complex ones, resulting in insufficient data for training a language model. In this work, we propose NegVerse, a method that tackles the lack of negation datasets by producing a diverse range of negation types from affirmative sentences, including verbal, non-verbal, and affixal forms commonly found in English text. We provide new rules for masking parts of sentences where negations are most likely to occur, based on syntactic structure and use a frozen baseline LLM and prompt tuning to generate negated sentences. We also propose a filtering mechanism to identify negation cues and remove degenerate examples, producing a diverse range of meaningful perturbations. Our results show that NegVerse outperforms existing methods and generates negations with higher lexical similarity to the original sentences, better syntactic preservation and negation diversity.
Type
Publication
In Adaptive Foundation Models at the 38th Conference on Neural Information Processing Systems (NeurIPS 2024)
In this work, we propose NegVerse, a data augmentation method for generating diverse negations from affirmative sentences. We introduce new masking rules based on syntactic structure to identify where negations are most likely to occur, and use a frozen baseline LLM with prompt tuning to generate negated sentences across verbal, non-verbal, and affixal forms.
A key contribution is the filtering mechanism that identifies negation cues and removes degenerate examples, ensuring the generated negations are both diverse and meaningful. Our experiments across five real-world datasets show that NegVerse outperforms existing methods in lexical similarity, syntactic preservation, and negation diversity — helping address the underrepresentation of negations in current NLP benchmarks and improving LLM robustness on negated statements.
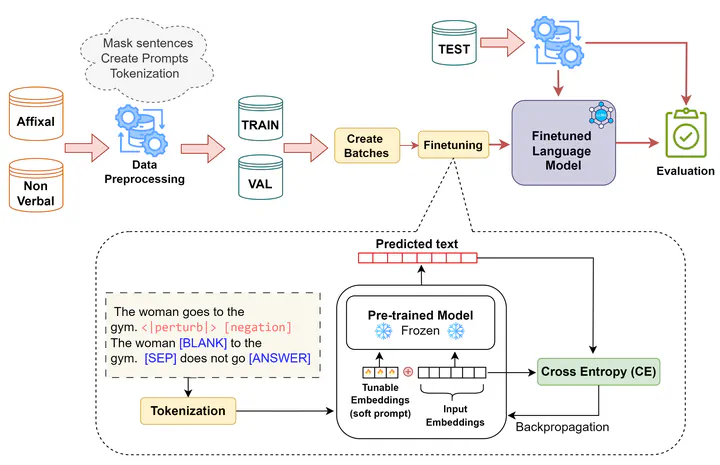 Figure credit: paper
Figure credit: paper