Abstract
Federated learning is a collaborative and distributed machine learning approach in which a statistical model is trained to solve an optimization problem using a federation of clients – such as different user devices or organizations – coordinated by a central server. During training, clients share only targeted updates designed to include the minimum information needed for the specific predictive task with the server, not the data itself. These updates are used by the server to improve the global model without directly accessing the clients’ data. The server is responsible for aggregating these updates and uses them to improve the global model. One of the key challenges in such learning settings is ensuring that the trained model is both accurate and unbiased with respect to various population groups that relate to demographics (e.g. gender, disability, sexual orientation or ethnicity). For instance, in the banking sector, federated learning is harnessed to develop more resilient models for credit score prediction, by aggregating information from multiple banks that hold data from different demographic backgrounds in a heterogeneous manner. Therefore, this work addresses federated demographic group fairness in two pragmatic federated learning scenarios. In the first learning scenario, we study federated (minimax) global group fairness where the target sensitive groups are known but the participating clients may only have access to a subset of the population groups during training. We discuss how the proposed group fairness notion differs from existing federated fairness criteria that impose similar performance across participants instead of demographic groups. We provide an algorithm to solve the proposed problem that enjoys the performance guarantees of centralized learning algorithms. We empirically compare the proposed approach against other methods in terms of group fairness in various setups, showing that our approach exhibits competitive or superior performance. In the second setting, we assume that the parties engaging in the federation are unaware of the target demographic groups and their corresponding group labels. To address this issue, we first introduce an objective that allows to learn a Pareto efficient global hypothesis ensuring (worst-case) group fairness. Our objective enables, via a single hyper-parameter, trade-offs between fairness and utility, subject to a group size constraint. The proposed objective recovers existing approaches as special cases, such as empirical risk minimization and subgroup robustness objectives from centralized machine learning. Next, we provide an algorithm to solve in federation a smoothed version of the proposed problem and prove that it exhibits convergence and excess risk guarantees. Our experiments indicate that our approach effectively improves the worst-performing group without unnecessarily hurting the average performance and achieves a large set of solutions with different fairness-utility tradeoffs. Finally, we demonstrate that its deployment can be beneficial even in some cases with known demographics. The methods proposed in this thesis have a generic nature, allowing for their application in various federated learning domains such as medicine, insurance, finance, and college admissions, among others.
Type
Publication
An open access version available from UCL Discovery
This thesis addresses federated demographic group fairness across two pragmatic and complementary settings.
In the first setting, sensitive groups are known but clients may only hold data from a subset of them during training. We propose FedMinMax, an algorithm that achieves minimax group fairness with performance guarantees matching those of centralised learning, and show formally how this notion of fairness differs from existing client-level criteria.
In the second setting, group labels are entirely unavailable. We introduce a flexible objective for learning a Pareto efficient model that guarantees worst-case fairness for any group above a minimum size, controlled via a single hyper-parameter. The resulting algorithm, FedSRCVaR, comes with convergence and excess risk guarantees, and empirically improves worst-group performance without degrading average accuracy.
Both methods are general-purpose and applicable across domains including medicine, finance, insurance, and college admissions. The thesis was passed without corrections.
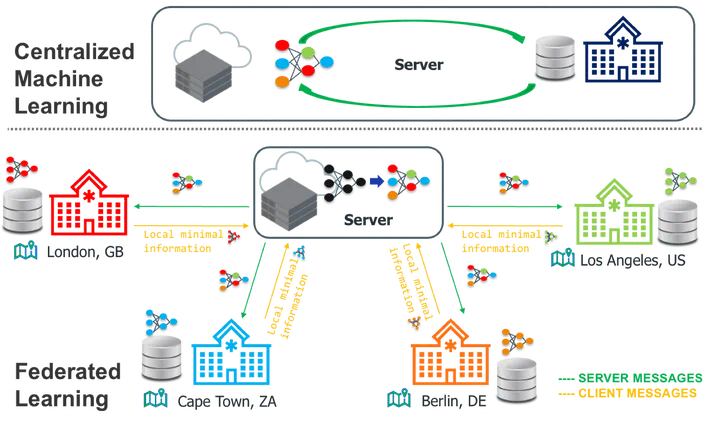 Image credit: paper
Image credit: paper