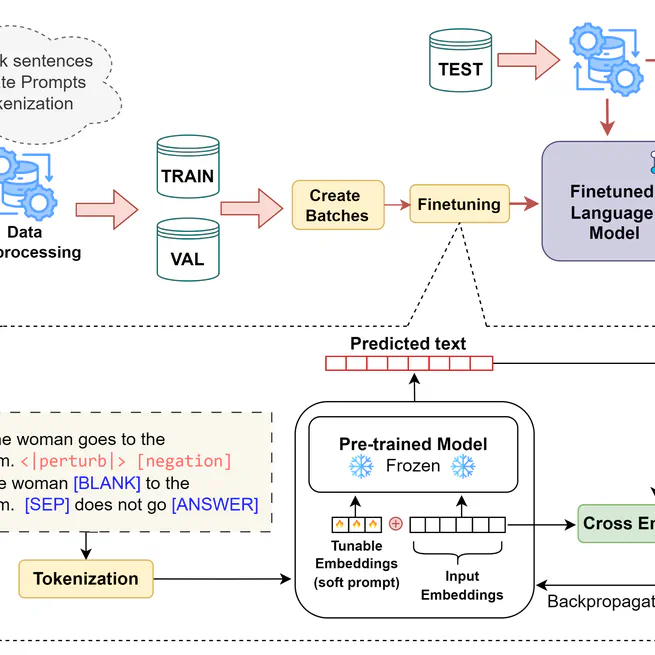
Generating Diverse Negations from Affirmative Sentences
In this work, we focus on improving the robustness of LLMs robustness on negated statements by proposingNegVerse, a data augmentation approach capable of generating various types of negations, including verbal, non-verbal, and affixal. We provide new masking rules and propose a filtering mechanism to identify negation cues and remove degenerate examples, producing diverse and in parallel meaningful negated sentences. We experiment with five real-world datasets and that NegVerse outperforms existing methods and generates negations with higher lexical similarity to the original sentences, better syntactic preservation, and greater negation diversity. Our empirical results also highlight that the proposed approach can generate negated sentences without specific guidance on blank placement. However, the resulting sentences exhibit reduced diversity compared to those generated with such guidance.
Nov 19, 2024
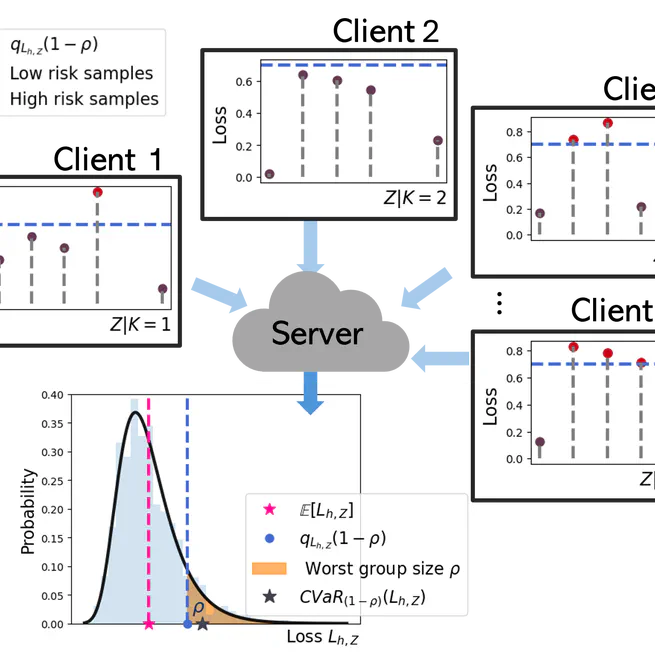
Federated Fairness without Access to Sensitive Groups
Federated learning is crucial to obtaining large, representative datasets across every sensitive group. Ensuring fairness across protected groups is essential for responsible machine learning, but prior knowledge of such groups is not always available, due to privacy constraints and evolving fairness requirements.This is the first work to present a flexible federated learning objective to ensure minimax Pareto fairness with respect to any group of sufficient size. We propose an algorithm that solves a proxy of the proposed objective, providing performance guarantees in the convex setting. Experimentally, our approach surpasses relevant FL baselines, exhibits comparable performance to centralized ML approaches, and demonstrates the ability to achieve a diverse range of solutions. For a single local epoch, FedSRCVaR is robust to data imbalances and heterogeneity across clients, yielding the same solution as centralized ML settings. For multiple local epochs, FedSRCVaR improves communication costs, but might yield a suboptimal solution when data are highly non-iid across clients
Feb 22, 2024
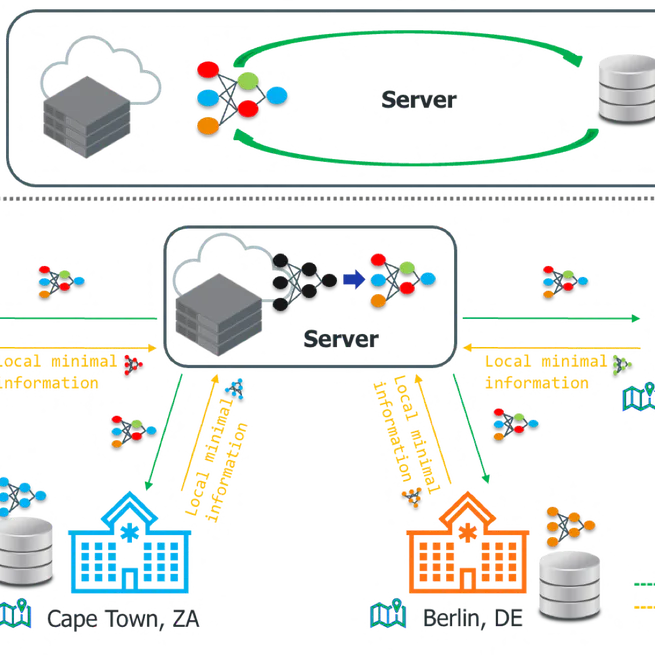
Fair Federated Learning
Federated learning is a collaborative and distributed machine learning approach in which a statistical model is trained to solve an optimization problem using a federation of clients – such as different user devices or organizations – coordinated by a central server. During training, clients share only targeted updates designed to include the minimum information needed for the specific predictive task with the server, not the data itself. These updates are used by the server to improve the global model without directly accessing the clients’ data. The server is responsible for aggregating these updates and uses them to improve the global model. One of the key challenges in such learning settings is ensuring that the trained model is both accurate and unbiased with respect to various population groups that relate to demographics (e.g. gender, disability, sexual orientation or ethnicity). For instance, in the banking sector, federated learning is harnessed to develop more resilient models for credit score prediction, by aggregating information from multiple banks that hold data from different demographic backgrounds in a heterogeneous manner. Therefore, this work addresses federated demographic group fairness in two pragmatic federated learning scenarios. In the first learning scenario, we study federated (minimax) global group fairness where the target sensitive groups are known but the participating clients may only have access to a subset of the population groups during training. We discuss how the proposed group fairness notion differs from existing federated fairness criteria that impose similar performance across participants instead of demographic groups. We provide an algorithm to solve the proposed problem that enjoys the performance guarantees of centralized learning algorithms. We empirically compare the proposed approach against other methods in terms of group fairness in various setups, showing that our approach exhibits competitive or superior performance. In the second setting, we assume that the parties engaging in the federation are unaware of the target demographic groups and their corresponding group labels. To address this issue, we first introduce an objective that allows to learn a Pareto efficient global hypothesis ensuring (worst-case) group fairness. Our objective enables, via a single hyper-parameter, trade-offs between fairness and utility, subject to a group size constraint. The proposed objective recovers existing approaches as special cases, such as empirical risk minimization and subgroup robustness objectives from centralized machine learning. Next, we provide an algorithm to solve in federation a smoothed version of the proposed problem and prove that it exhibits convergence and excess risk guarantees. Our experiments indicate that our approach effectively improves the worst-performing group without unnecessarily hurting the average performance and achieves a large set of solutions with different fairness-utility tradeoffs. Finally, we demonstrate that its deployment can be beneficial even in some cases with known demographics. The methods proposed in this thesis have a generic nature, allowing for their application in various federated learning domains such as medicine, insurance, finance, and college admissions, among others.
Oct 1, 2023
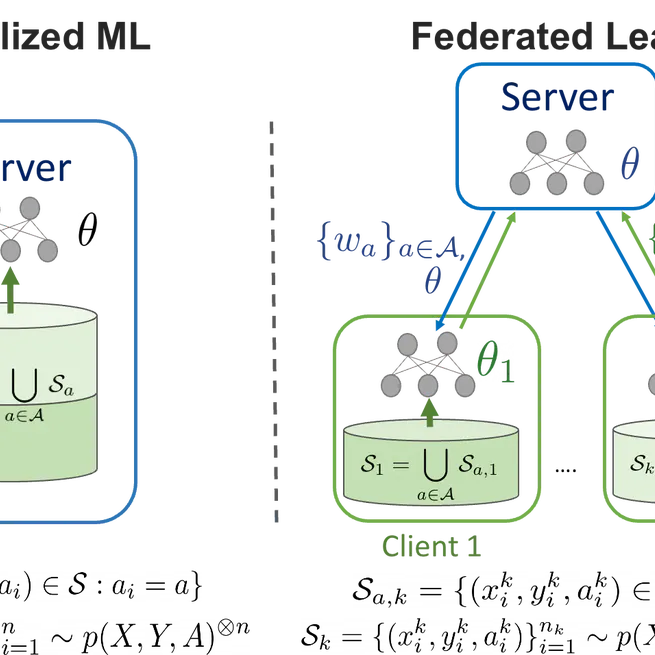
Minimax Demographic Group Fairness in Federating Learning
In this work, we formulate (demographic) group fairness in federated learning setups where different participating entities may only have access to a subset of the population groups during the training phase (but not necessarily the testing phase), exhibiting minmax fairness performance guarantees akin to those in central-ized machine learning settings. We formally show how our fairness definition differs from the existing fair federated learning works, offering conditions under which conventional client-level fairness is equivalent to group-level fairness. We also provide an optimization algorithm, FedMinMax, to solve the minmax group fairness problem in federated setups that exhibits minmax guarantees akin to those of minmax group fair centralized machine learning algorithms. We empirically confirm that our method outperforms existing federated learning methods n terms of group fairness in various learning settings and validate the conditions under which the competing approaches yield the same solution as our objective.
Jun 20, 2022
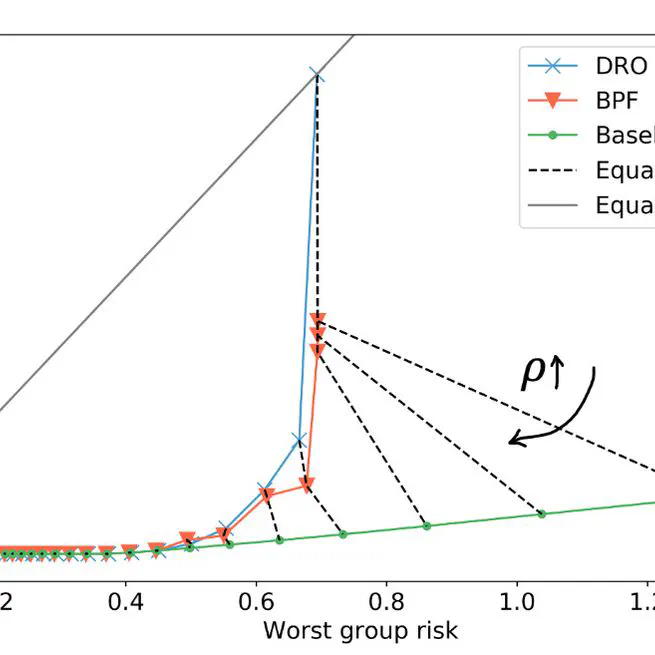
Blind pareto fairness and subgroup robustness
In this work we formulate and analyze subgroup robustness, particularly in the context of fairness without demographics or labels. Our goal is to recover a model that minimizes the risk of the worst-case partition of the input data subject to a minimum size constraint, while we additionally constrain this model to be Pareto efficient w.r.t. the low-risk population as well. This means that we are optimizing for the worst unknown subgroup without causing unnecessary harm on the rest of the data. We show that it is possible to protect high risk groups without explicit knowledge of their number or structure, only the size of the smallest one, and that there is a minimum partition size under which the random classifier is the only minimax option for cross-entropy and Brier score losses.
Jun 10, 2021